Healthcare AIArchived
ILA
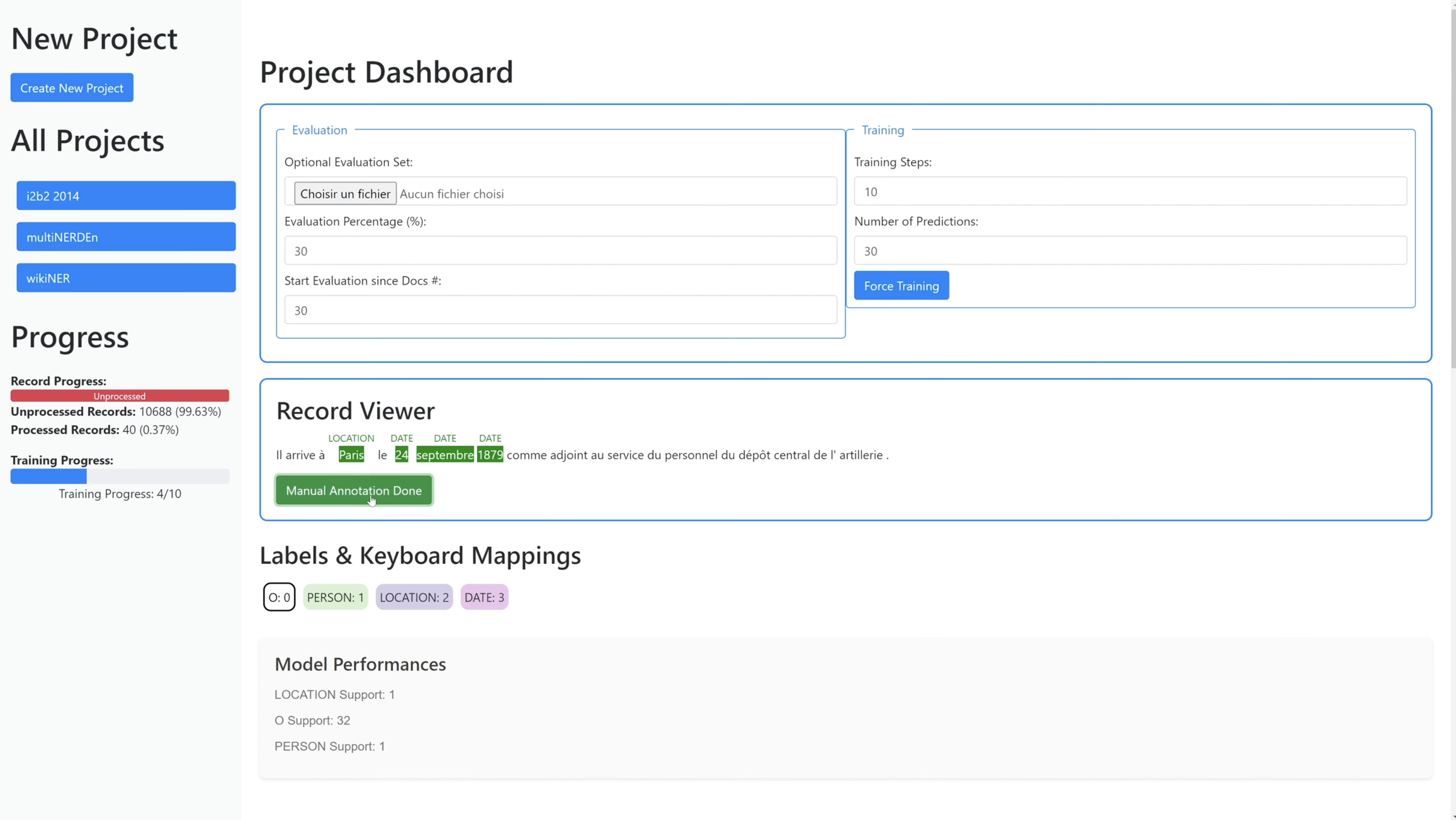
Clinical Data Anonymization
AI system for medical data de-identification using fine-tuned language models. Enables privacy-compliant processing of clinical documents. Born from my Master's thesis at UCLouvain.
Visit projectPrivacy-compliant healthcare data processing
Fine-tuned LLMsNERHealthcarePrivacy